How does Git think of Data?
The way Git thinks of data is different from the way many other version control systems think of data. Many version control systems store data as a list of files and changes to the files over a period of time. They are delta based.
Git on the other hand thinks of data as a series of snapshots. So, whenever you make a commit, Git takes a snapshot of the entire state of project at that particular point of time and stores it. It also maintains a reference to that snapshot.
So let's say at the start, you have 3 files: A, B and C. When you make a commit, Git takes a snapshot of the entire state of project at this point and stores it.
Now, if you edit files A and C and make another commit, Git takes another snapshot of the entire state of the project at this point of time and stores it.
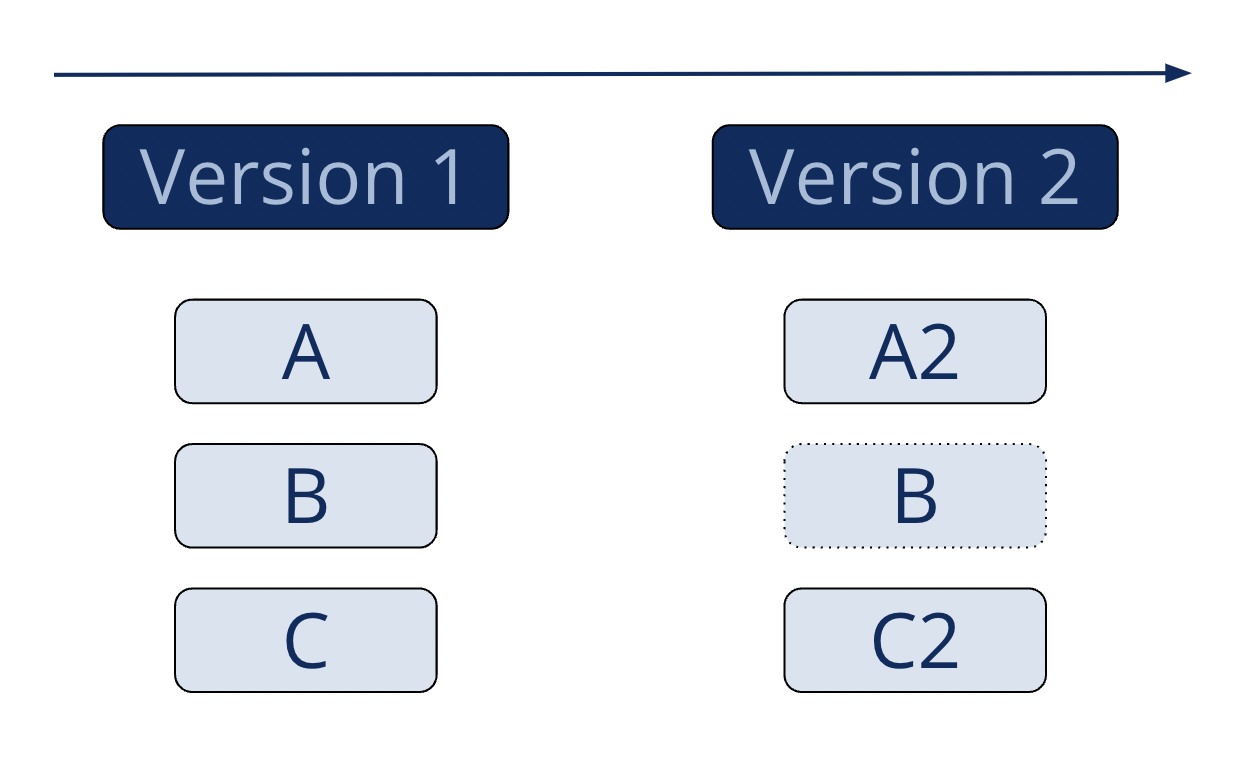 Since file B has not changed, Git doesn’t store that file again. It maintains a link to the previous identical file it has already stored.
Since file B has not changed, Git doesn’t store that file again. It maintains a link to the previous identical file it has already stored.